Integrating Cloud Data into Existing SQL Workflows with Cloud2SQL

One of the key features of Resoto is its ability to collect data from a wide range of cloud providers, including Amazon Web Services (AWS), DigitalOcean, and Google Cloud. This makes it easy to get a comprehensive view of your cloud infrastructure, no matter where it is deployed.
But, what sets Resoto apart from other cloud data collection tools is its ability to enrich the data it collects and make additional connections. This means that Resoto not only gathers raw data about your cloud resources, but also adds additional context and information that can help you better understand your cloud environment.

For example, when collecting data about Elastic Block Store (EBS) volumes in AWS, Resoto uses Amazon CloudWatch time series data to find out when a volume had its last read and write I/O. This information is then used to enrich the raw volume data with last_access and last_update timestamp properties, which makes it easy to answer when a particular EBS volume was last used, not just that it is not in use right now.
Resoto also makes additional connections—for instance, between your K8S clusters and the underlying cloud provider systems. As a result, you can easily see how your Kubernetes pods are related to the virtual machines that they are running on, and how those virtual machines are related to the storage volumes that they are using. This provides valuable insights into the structure and organization of your cloud environment, and helps you make better decisions about how to manage and optimize it.
The data collected by Resoto is complex and deeply nested, with many levels of dependencies between different cloud resources. To manage this complexity, Resoto uses a graph data model where each cloud resource is represented by a node in the graph with edges connecting dependent nodes.
Let us take a closer look at the dependencies of an AWS Elastic Load Balancer (ELB):

Here, we see a load balancer is part of a Virtual Private Cloud (VPC) and subnet, and there are EC2 instances underneath an ELB. We also see that sometimes Amazon's Elastic Container Service (ECS) creates ELBs, as there's an edge from a ECS service to the ELB kind.
To represent an individual node, Resoto uses a unified data model with strict typing and support for inheritance. This has the advantage that you can either ask for all of your infrastructure's load balancers, or you can ask for AWS ELBs specifically. Speaking of which, here is the model for an ELB:

As you can see, every aws_elb inherits load_balancer, which in turn inherits from resource. Each aws_elb also contains additional data like aws_elb_policies, which contain an aws_elb_app_cookie_stickiness_policy and aws_elb_lb_cookie_stickiness_policy, and so on.
Example of an individual aws_elb
{
"id": "hgoa3433hOo7j6pEUDmozE",
"type": "node",
"revision": "_fH7wa0K--I",
"reported": {
"kind": "aws_elb",
"id": "blogtest-apiserver-526928195.us-west-2.elb.amazonaws.com",
"name": "blogtest-apiserver",
"ctime": "2022-11-22T09:14:30Z",
"tags": {
"owner": "lukas",
"sigs.k8s.io/cluster-api-provider-aws/role": "apiserver",
"sigs.k8s.io/cluster-api-provider-aws/cluster/blogtest": "owned",
"Name": "blogtest-apiserver"
},
"lb_type": "elb",
"backends": [
"i-08381208b144af211"
],
"scheme": "internet-facing",
"elb_canonical_hosted_zone_name": "blogtest-apiserver-526928195.us-west-2.elb.amazonaws.com",
"elb_canonical_hosted_zone_name_id": "Z2H1FL2FABSF3",
"elb_listener_descriptions": [
{
"listener": {
"protocol": "TCP",
"load_balancer_port": 6443,
"instance_protocol": "TCP",
"instance_port": 6443
},
"policy_names": []
}
],
"elb_policies": {
"app_cookie_stickiness_policies": [],
"lb_cookie_stickiness_policies": [],
"other_policies": []
},
"elb_backend_server_descriptions": [],
"elb_availability_zones": [
"us-west-2c",
"us-west-2b",
"us-west-2a"
],
"elb_health_check": {
"target": "SSL:6443",
"interval": 10,
"timeout": 5,
"unhealthy_threshold": 3,
"healthy_threshold": 5
},
"elb_source_security_group": {
"owner_alias": "999264467951",
"group_name": "blogtest-apiserver-lb"
}
}
}
While a graph data model is well-suited to representing the complex and hierarchical data collected by Resoto, the reality is that many people are familiar with SQL and the traditional database model based on rows and columns. SQL is a mature and well-established language, with a rich ecosystem of tools and applications.
To provide users with the option to use SQL with the data collected by Resoto, we developed Cloud2SQL, a sub-project of Resoto. Cloud2SQL is based on the same rich data collected by Resoto, but it flattens that data into tables, complete with foreign keys and link tables.
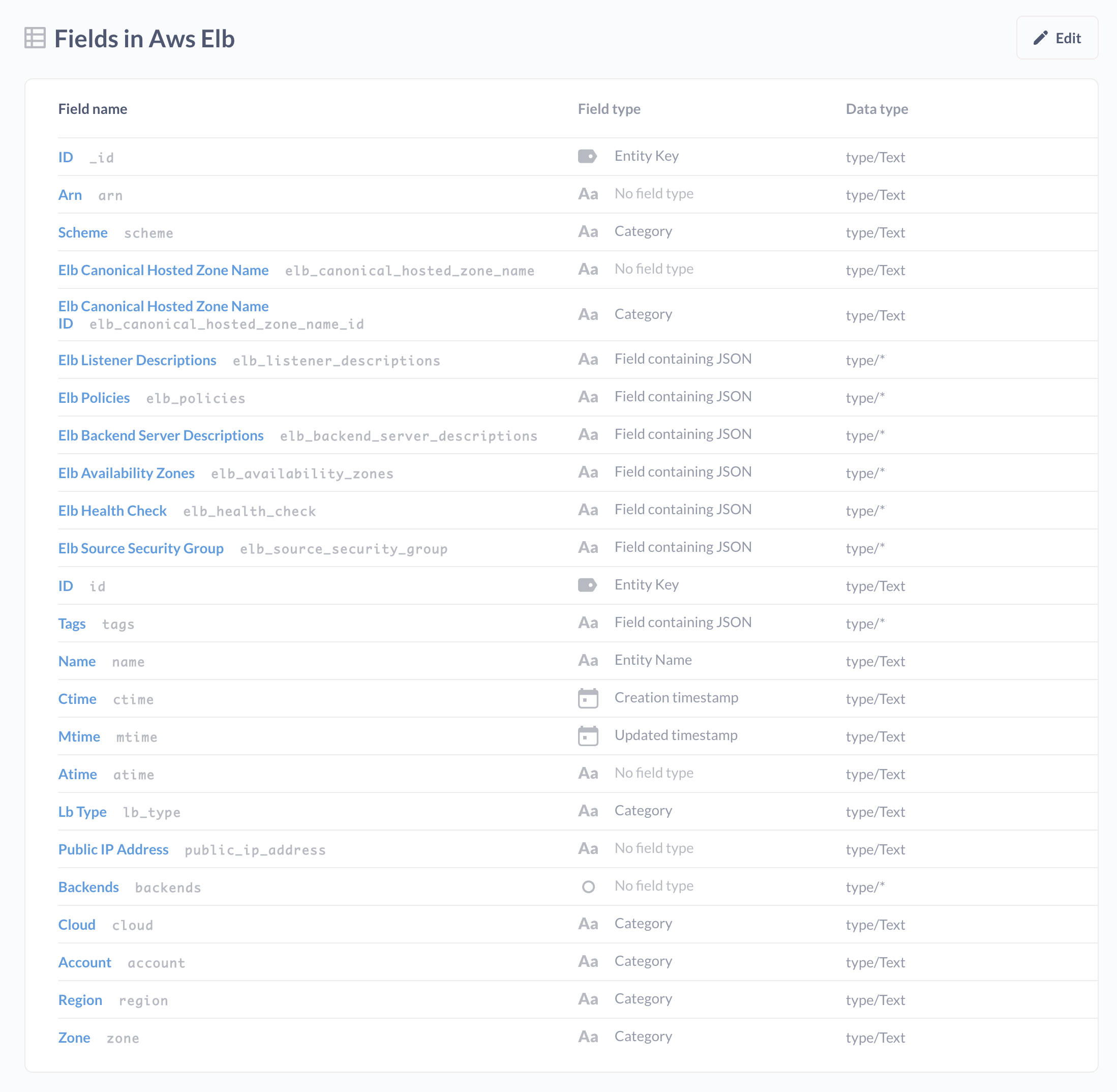
A link table is a special type of table that allows you to easily find relationships between different resources.
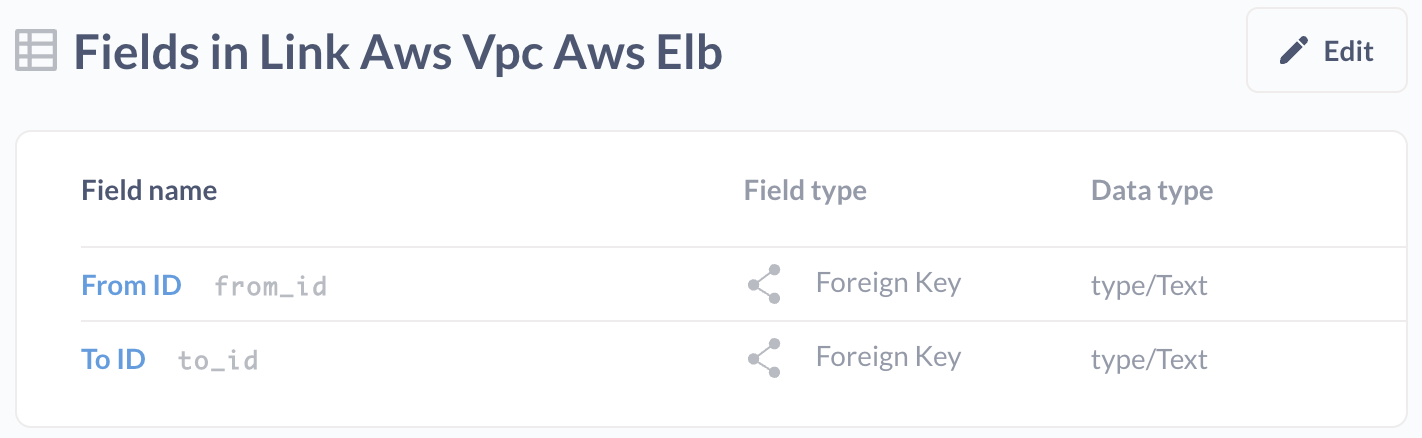
Each link table is prefixed with link_ followed by the two resource kind names. For example, a link table connecting an AWS VPC to an AWS ELB would be named link_aws_vpc_aws_elb.
Link tables only have two fields: from_id and to_id, which can be easily JOINed on.
To illustrate how link tables work, consider the following SQL query:
SELECT aws_elb.name, aws_vpc.name
FROM aws_elb
INNER JOIN link_aws_vpc_aws_elb ON aws_elb._id = link_aws_vpc_aws_elb.to_id
INNER JOIN aws_vpc ON aws_vpc._id = link_aws_vpc_aws_elb.from_id
LIMIT 1;
This query would return the name of an AWS ELB and the name of the VPC it is connected to. By using link tables, you can find dependent resources without needing to know the specific details of each resource's API or how the resources are related. Much like when working with a graph you can also find resources based on the state of another resource.
All of this allows users who are familiar with SQL to easily work with the data collected by Resoto, using the tools and applications with which they are already familiar. It also makes it easy to integrate the data collected by Resoto into existing SQL-based workflows and processes.
Cloud2SQL is stateless and runs standalone, independently of Resoto. It is, however, based on the same collector plugins that Resoto uses to gather data.
Cloud2SQL already has support for writing to a variety of different destinations, including SQLite files, MySQL, MariaDB, and PostgreSQL databases, the Snowflake cloud-based data warehousing platform, and Parquet columnar structure files. This allows users to choose the destination that best fits their needs and workflows. By supporting a range of different destinations, Cloud2SQL makes it easy to work with the data collected by Resoto in the way that is most convenient for you.
In Installing Cloud2SQL, we'll take a closer look at Cloud2SQL, install and configure it, and see how it can be used to get insights into our cloud infrastructure.
Lastly, we are currently busy integrating the SQL synchronization functionality into Resoto as well. Much like we are using Resoto collector plugins to power Cloud2SQL, we will be using Cloud2SQL's table generation and export functionality inside Resoto. The main difference between the two tools is that Cloud2SQL is a stateless, standalone tool that does data export only, while Resoto is a stateful collection of services that can not only export data and provide visibility but also be configured to take action.
